

You have your local homelab in which you store all your data. You have set up security measures to avoid data loss: parity disk, hot spare, cold spare, RAID, … But in the event that your server burns down, a power surge fries your server and the data it contains, … are you ready?
What’s the 3-2-1 Backup Rule ? #
The term 3-2-1 was coined by US photographer Peter Krogh while writing a book about digital asset management in the early noughties.
- 3: The rule said there should be three copies of data. One is the original or production copy, then there should be two more copies, making three.
- 2: The two backup copies should be on different media. The theory here was that should one backup be corrupted or destroyed, then another would be available. Those threats could be IT-based, which dictated that data be held in a discrete system or media, or physical.
- 1: The final “one” referred to the rule that one copy of the two backups should be taken off-site, so that anything that affected the first copy would not (hopefully) affect it. — computerweekly.com

3-2-1 Backup Rule allows to store data with almost no risk of loss. Today many people agree that this rule does not really make sense with the arrival of the cloud. Indeed, providers such as Google, Amazon, … have replication systems on several disks, but especially in several locations. All this remains invisible for the user, but these securities are well present.
In our case the NAS, depending on how it is configured, has a security for data loss related to the death of a disk: Parity, RAID, … This can be considered as 2 copies. But as said in the intro, these 2 copies are in the same server and at best in the apartment/home. If there is a fire, there may be 2 copies, both will go up in smoke.
To stay in the Homelab philosophy, the ideal would be to have the possibility to deploy a second server in another location (spaced of several kilometers as far as possible) and to make a replication of the data. This solution, although ideal, is not possible for everyone, either in terms of cost or the possibility of having a space where to put the server.
That’s why I tried to find another solution. This solution is the Cloud! For cheap, or even free, we will be able to save our data more important in an automatic way. With even a version system to keep up to 30 days of history!
Cloud Provider #
The choice of cloud provider is quite personal, in my case I chose Google Drive because I already had an account and I know that there is a history feature integrated.
Depending on the space you want, it may be more interesting to explore other options.
Rclone offers a large selection for which you can find a list at the following address: https://rclone.org/
Rclone setup #
Once you have chosen your cloud provider, you must now set it up on your server to be able to make backups.
In my case I will follow the tutorial for Google Drive at the following address: Link. There are also guides for the different solutions on the Rclone website but I found that they were not as complete.
Once the configuration is done I can check that it works with the following command:
xxxxxx@Mark1:~# rclone about google:
Total: 100 GiB
Used: 3.504 GiB
Free: 93.562 GiB
Trashed: 3.746 MiB
Other: 2.934 GiBBackup setup #
Now that we have access to our cloud provider, we just need to automate the backup. This first script allows us to mountour cloud folder in order to access it:
#!/bin/bash
mkdir -p /mnt/disks/google
rclone mount --max-read-ahead 1024k --allow-other google: /mnt/disks/google &This second script allows to unmount the cloud folder if we stop the server:
#!/bin/bash
fusermount -u /mnt/disks/googleThis last script is the most important one, it’s here that we choose what to save! First I create an archive save_mark1.zip in which I add as many folders as I want. In the example I add /mnt/user/d3vyce and /mnt/user/appdata/ghost. Then I clone the archive on the cloud provider set up before: Google. Finally I delete the archive locally.
#!/bin/bash
zip -r /tmp/save_mark1.zip /mnt/user/d3vyce /mnt/user/appdata/ghost [...]
rclone sync /tmp/save_mark1.zip google:save_mark1
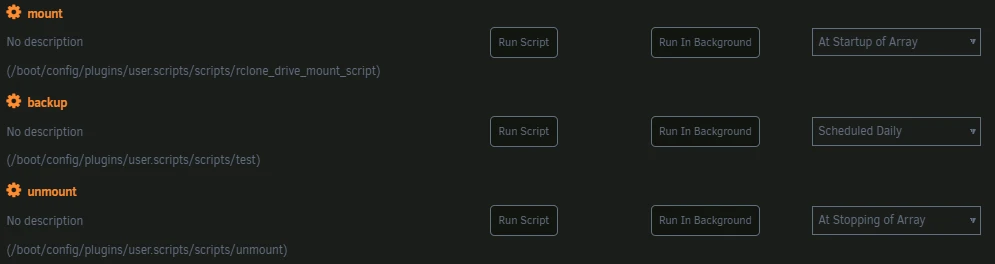
rm /tmp/save_mark1.zipIn the script plugin of Unraid I add the different scripts with the following execution conditions:
- mount -> At Startup of Array
- backup -> Scheduled Daily
- unmount -> At Stopping of Array
This should result in the following:
After waiting one day I check on the drive that the backup has been done:
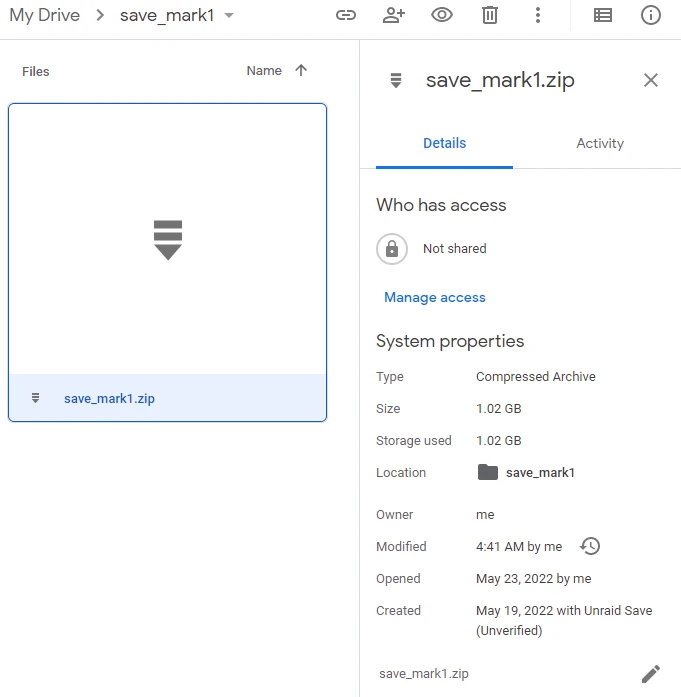
And indeed there is an archive of about 1Gb that has been uploaded in the save_mark1 folder. The system works !
I then let the script run for several days to see if the history system works well. As you can see I have a history of the file for about 30 days. An interesting thing to know is that only the archive consumes space on my drive and not all the versions in the history. This makes it consume ~1Gb with 30 versions of the archive accessible.

Conclusion #
In conclusion this solution is clearly very practical and potentially free depending on the amount of data you want to backup. There are a lot of features possible with Rclone (data encryption, logging, …) I let you explore!
In my case it allows me to save sensitive data such as the database of this blog for which I had no offsite backup.


